0. 阅读收获 (takeaway)
读完本文,你将了解:
- Context Rot(上下文腐烂):为什么更大的 context window 不是万能解药
- Cache-Safe Compaction:如何在压缩 context 时不破坏 cache
- Plan 模式的演进:从 todo.md 到专门 planner agent
- 文件系统 & Just-in-Time Context:Agent 的"延展记忆"
- 子代理的 Cache 友好设计:90%+ prefix reuse 是怎么做到的
- The Bitter Lesson:哪些设计是持久的,哪些会被模型进步淘汰
前置知识:本文是 Agent 系统中的 Prompt Caching 设计(上) 的续篇。如果你还没读过,建议先了解 Cache 破坏机制、Prompt 布局和工具管理策略。更基础的概念见 理解 KV Cache 与 Prompt Caching。
1. Context Rot:上下文腐烂
Anthropic 的研究指出:随着 context 中 token 增加,模型注意力分散,性能下降。
Attention 中每个 token 要和所有其他 token 建立 $n^2$ 的 pairwise 关系。Context 越长 → 每个 token 的"注意力预算"越少 → 模型可能"忘记"早期的重要指令,或被大量 tool output 稀释关键信息。
更大的 context window 不是万能解药。 能塞进去不代表模型能有效利用。
这就是为什么 Agent 不能简单地把所有信息堆进 context——我们需要主动管理。
2. Compaction:Cache-Safe 的上下文压缩
压缩是解决 context 增长的关键手段,但必须是 cache-safe 的。
2.1 Claude Code 的 Cache-Safe Compaction
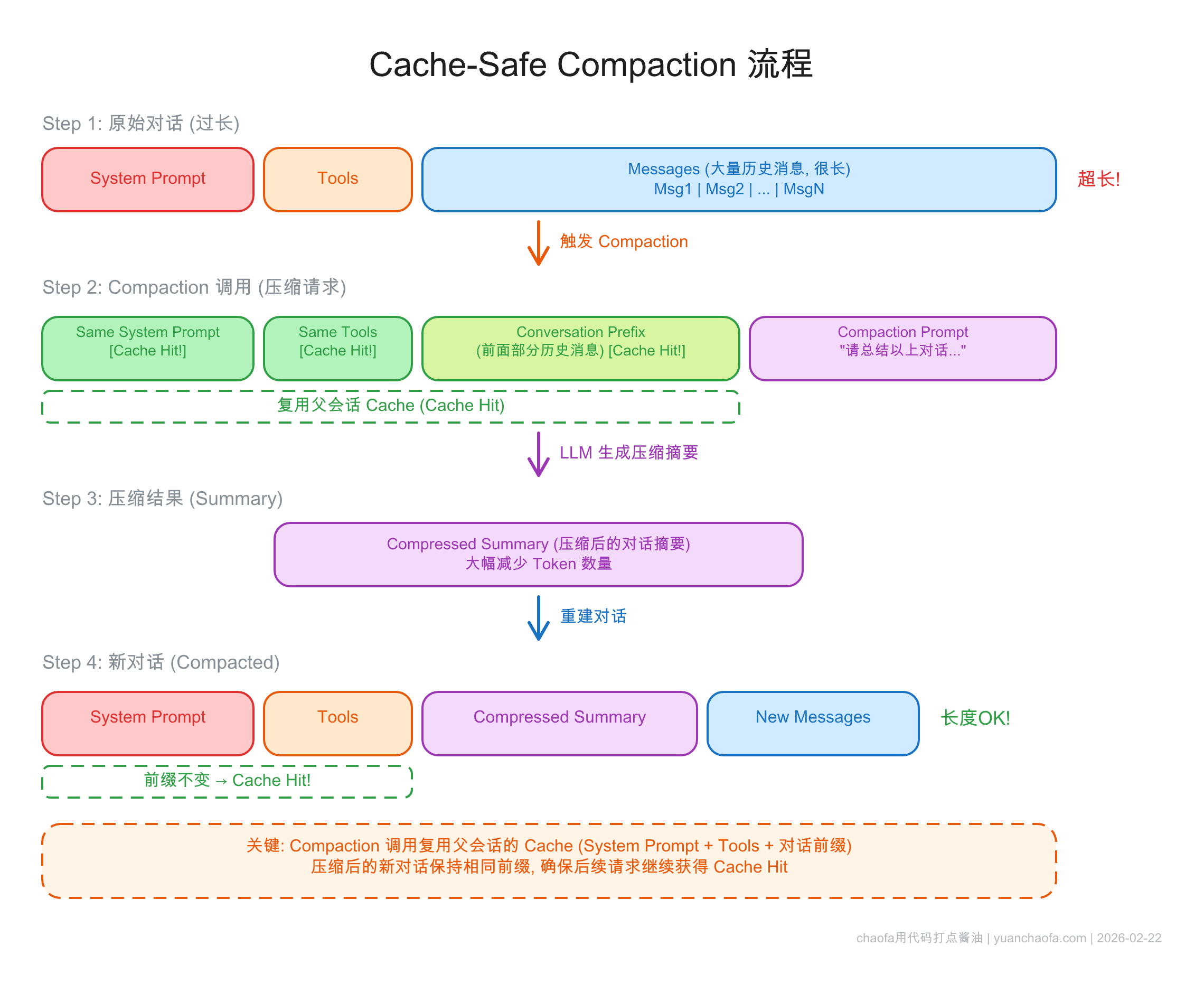
Claude Code 的压缩策略非常精巧:
- 压缩请求使用完全相同的 system prompt + tools + 对话前缀
- 只在末尾追加 compaction prompt
- 这样压缩请求本身就能复用父会话的 cache
- 预留 "compaction buffer"——context 快满之前就开始压缩
2.2 OpenAI Codex 的 /responses/compact
Codex 提供专门的 API 端点:
- 返回压缩后的 item 列表 + encrypted compaction 项目
- 保留模型对原始对话的"潜在理解"(指的是把 summary 内容放到上下文中)
- 超过
auto_compact_limit自动触发
两者共同点:压缩是必要的,但压缩过程本身不能破坏已有的 cache。
3. 注意力操纵:Plan 模式的演进
Agent 如何确保模型"聚焦"在正确的事情上?三家有一个有趣的演进过程。
3.1 Manus 的演进
- 初期用
todo.md→ 约 1/3 actions 浪费在更新 todo 上! - 最新:专门的 planner agent 替代 → 效率大幅提升
3.2 Claude Code 的 Plan Mode
- 独立规划阶段 → 用户审批 → 再执行
- 模型可自主调用
EnterPlanMode
3.3 Codex 的 update_plan
- 执行中的一个工具
- 无需用户审批,更轻量
| 方案 | 独立阶段? | 用户审批? | 自主控制? |
|---|---|---|---|
| Manus planner agent | 独立 agent | 无需审批 | Agent 决定 |
| Claude Code Plan Mode | 独立阶段 | 需要审批 | 模型可自主进入 |
| Codex update_plan | 也有独立阶段 | 无需审批 | 执行中随时调用 |
4. 保留错误内容
一个有趣的共识:不要删除失败的 action 和 observation。
Manus 不会从 context 中删除失败的工具调用结果。双重好处:
- 保持 append-only → 保护 cache
- 模型从错误中学习 → 调整后续策略
错误恢复是真正 agentic 行为的标志。 看不到自己犯的错,怎么学会避免?
5. 文件系统 & Just-in-Time Context
Agent 不需要把所有信息都放在 context 里——文件系统可以作为"延展记忆"。
5.1 Manus 的文件系统策略
- 文件系统当"无限 context":执行结果写入文件,context 只保留引用
- Full vs Compact 表示:新结果保留完整内容(文件读写的结果),旧结果替换为文件路径引用(压缩的时候,这时候看上去已经破坏了 prompt caching)。来源于:Manus webinar notes (2025.10): Context Reduction/Isolation/Offloading
- 备注,这里有点没看懂。「括号()部分的内容是我加的,是我个人的理解」。
- 压缩后通过重新读取文件恢复信息
- MCP 工具通过 CLI 在沙盒执行,避免工具列表膨胀
5.2 Just-in-Time 检索
| 方案 | 预加载 | 按需检索 |
|---|---|---|
| Claude Code | CLAUDE.md | glob/grep 搜索文件系统 |
| Codex | AGENTS.md | shell 工具探索 |
| Anthropic 建议 | 最少必要信息 | JIT 检索 |
共同点:用 glob/grep 搜索文件系统,无需向量索引。这和 Agentic RAG 的思路一脉相承——Agent 自主决定搜索什么,而不是被动接受检索结果。
6. 子代理架构与模型选择
6.1 不要在会话中切换模型
Cache 是 model-specific 的。各家的做法:
- Claude Code:Sub-Agent handoff(Opus → Haiku for Explore)
- Codex:同一对话保持同一模型
- Manus:任务级路由(Claude 做代码,Gemini 做多模态,OpenAI 做数学)——不同任务不同模型,但单次对话内不变
6.2 子代理的 Cache 友好设计
Claude Code 架构(逆向分析数据):
| 子代理 | 工具数 | Prefix Reuse |
|---|---|---|
| Main Agent | 18 | — |
| Explore × 3 并行 | 10/18 子集 | 92% |
| Plan | 独立 context | 93% |
| Execution | 全部 | 97% |
Claude Code 还使用 warm-up 调用:启动时预热 tool list 和 system prompt 的 cache。
Manus 多代理架构:
- Planner → Knowledge Manager → Executor 三层
- 子代理有
submit_results工具 + 约束解码确保输出格式
Anthropic 建议:子代理返回压缩 summary → 避免主 context 被"污染"。
6.3 Fork 操作必须共享父 prefix
Fork 出的子任务必须用和父对话相同的 prompt prefix,才能复用父对话 cache。
Claude Code 在 compaction、summarization、skill execution 中都遵循这个原则。核心思想:压缩/fork 是在现有 cache 基础上的延伸,而非另起炉灶。
7. The Bitter Lesson
最后分享 Manus 的反思,引用 Rich Sutton 的 "The Bitter Lesson":
Agent 的 harness(框架/约束)可能限制模型性能。随着模型进步,需要不断简化架构。
Manus 自 2025 年 3 月以来已重构无数次。每次模型能力提升,某些 workaround 就变得不必要。
但有些设计是"持久"的——围绕 cache 的架构决策就是。它们不是在弥补模型不足,而是在适配计算的物理现实。
Cache 是物理约束,不是工程 hack。 只要 Prefill 还是 Compute Bound,Prompt Cache 就会继续是 Agent 架构的核心考量。
参考
备注:本文主要受前 4 篇参考内容的启发
- Thariq @trq212 - Lessons from Building Claude Code: Prompt Caching Is Everything
- Lance Martin - Manus webinar notes (2025.10): Context Reduction/Isolation/Offloading
- Manus Blog - Context Engineering for AI Agents
- 深入解析 Codex 智能体循环
- Effective Context Engineering for AI Agents
- Agent Prompt Cache 设计(上):Cache 破坏、Prompt 布局与工具管理 - 本博客
- 理解 KV Cache 与 Prompt Cache - 本博客
- RAG 进化之路:传统 RAG 到 Agentic RAG - 本博客
