在阅读本文之前,强烈建议先阅读原始paper和苏剑林的解读 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA,先在脑子中对于 MLA(Multi-head Latent Attention)有一个大概的印象,然后通过阅读代码理解下面三个问题
- MLA 大概是个什么东西,核心目标是节约 kv cache
- 可以理解为效果更好的 Group Query Self Attenion。
- 为什么 MLA 算法和 ROPE 位置编码不兼容,MLA 算法是通过维度分离来实现位置编码
- 也就是说一部分 Q 和 K 专门做位置编码,称为 $q_{rope}$ 和 $k_{rope}$,一部分不做位置编码,称为 $q_{nope}$ 和 $k_{nope}$
- 两部分做 concat 后去计算 $q = concat(q_{rope}, q_{nope})$ 和 $k = concat(k_{rope}, k_{nope})$ 的 attention weight;然后计算 qkv 最终的输出,具体见 代码;
- MLA 既然能节约 kv cache,那么具体是怎么通过矩阵吸收来做工程实现
- 这部分Paper以及官方开源实现没有给出
如果不想看文字,可以看B站手把手教学视频: Part 1: 从零复现 DeepSeek MLA 算法-无矩阵吸收版 Part 2: 从零手撕 DeepSeek MLA 算法-矩阵吸收版
也欢迎关注我的 github repo: LLMs-zero-to-hero
原始的 MLA 算法
一图胜千言,先通过 DeepSeek-V2/3 对应的官方模型图理解 MLA 算法。
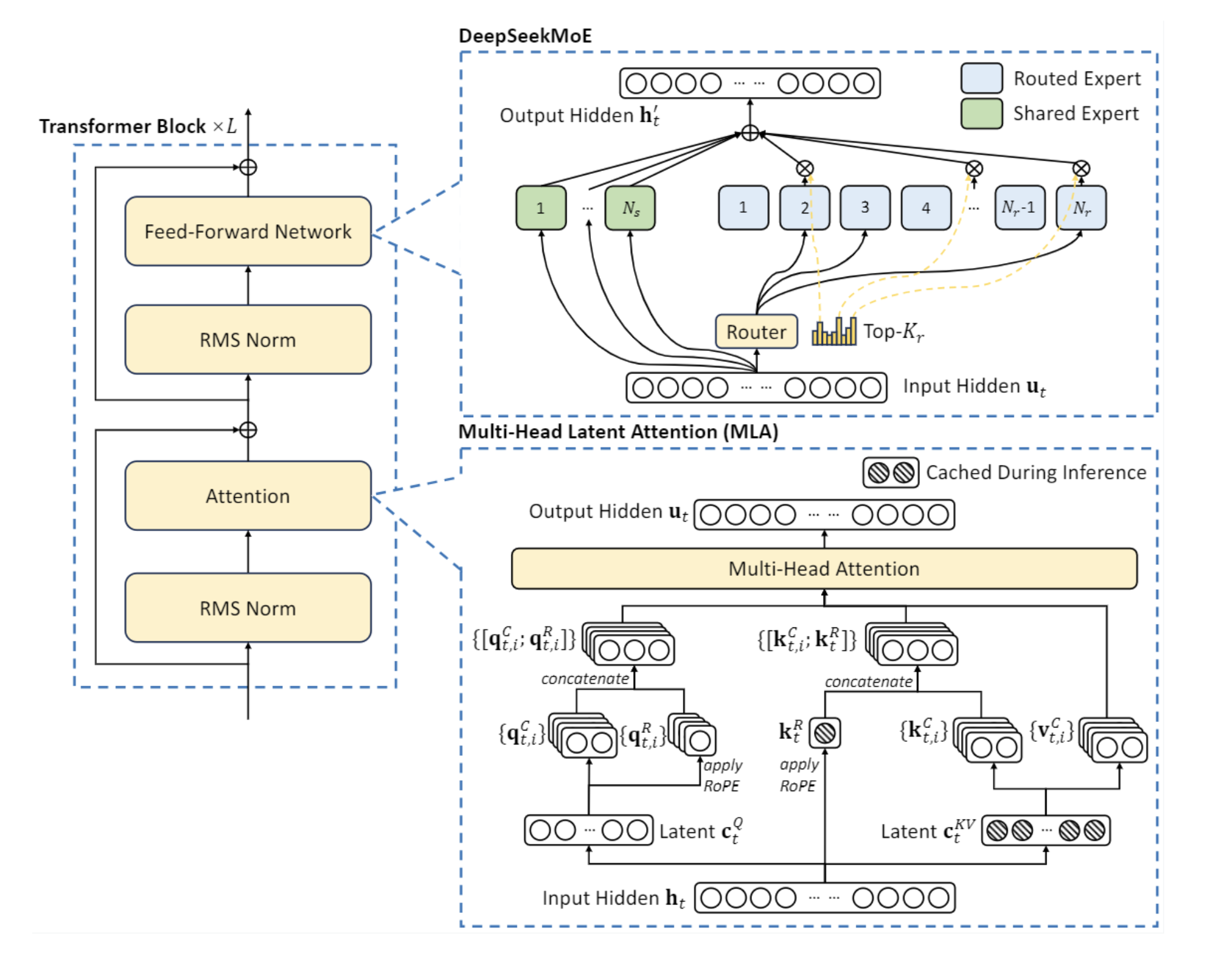
一些前置函数,主要是两个函数,一个 RMSNorm 的实现以及 ROPE 函数的实现,因为本次博客不涉及位置编码的解读,因此可以先简单把 ROPE 理解为一个函数,应用这个函数之后这部分张量(Tensor)就带有了位置编码的作用。
class DeepseekV2RMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
class DeepseekV2RotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
inv_freq = 1.0 / (
self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim)
)
self.register_buffer("inv_freq", inv_freq, persistent=False)
# 较小索引位置对应较低频率
# 较大的索引位置有较高的频率
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=max_position_embeddings,
device=self.inv_freq.device,
dtype=torch.get_default_dtype(),
)
self.max_seq_len_cached = None
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(
self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype
)
freqs = torch.outer(t, self.inv_freq.to(t.device))
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if self.max_seq_len_cached is None or seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
self.cos_cached[:seq_len].to(dtype=x.dtype),
self.sin_cached[:seq_len].to(dtype=x.dtype),
)
# Copied from transformers.models.llama.modeling_llama.rotate_half
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
b, h, s, d = q.shape
q = q.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
b, h, s, d = k.shape
k = k.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
最终的代码实现,主要通过代码的注释理解,以及对应的 B站视频讲解;原始代码实现位于: https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/tree/main
以下代码相对于官方代码实现进行了一些必要的精简,主要为了理解 MLA 算法的核心计算逻辑,对于部分工程实现进行了忽略。
from dataclasses import dataclass
@dataclass
class DeepseekConfig:
hidden_size: int
num_heads: int
max_position_embeddings: int
rope_theta: float
attention_dropout: float
q_lora_rank: int
qk_rope_head_dim: int
kv_lora_rank: int
v_head_dim: int
qk_nope_head_dim: int
attention_bias: bool
class MLA(nn.Module):
def __init__(self, config,):
super().__init__()
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_heads
self.max_postion_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
# 对应 query 压缩的向量, 在 deepseek v3 中, hidden_size 7168
# 但是压缩后的 kv d_c= 512,压缩比例 1/14
# q 的压缩为 1536 压缩比例 1/4.7
# rope 部分是 64
self.q_lora_rank = config.q_lora_rank
# 对应 query 和 key 进行 rope 的维度
self.qk_rope_head_dim = config.qk_rope_head_dim
# 对应 value 压缩的向量
self.kv_lora_rank = config.kv_lora_rank
# 对应 每一个 Head 的维度大小
self.v_head_dim = config.v_head_dim
self.qk_nope_head_dim = config.qk_nope_head_dim
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.q_down_proj = nn.Linear(
self.hidden_size,
self.q_lora_rank,
bias=config.attention_bias,
)
self.q_down_layernorm = DeepseekV2RMSNorm(self.q_lora_rank)
self.q_up_proj = nn.Linear(
self.q_lora_rank,
self.num_heads * self.q_head_dim,
# 最终还需要做切分(split),一部分是 nope,一部分需要应用 rope
bias=False,
)
# 同理对于 kv 也是一样的
self.kv_down_proj = nn.Linear(
self.hidden_size,
self.kv_lora_rank + self.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_down_layernorm = DeepseekV2RMSNorm(self.kv_lora_rank)
self.kv_up_proj = nn.Linear(
self.kv_lora_rank,
self.num_heads * (
self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim
), # 其中 self.q_head_dim - self.qk_rope_head_dim 是 nope 部分
bias=False,
)
# 对应公式 47 行
self.o_proj = nn.Linear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=config.attention_bias,
)
# 初始化 rope 的参数
self.rotary_emb = DeepseekV2RotaryEmbedding(
self.qk_rope_head_dim,
self.max_postion_embeddings,
self.rope_theta,
)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""
MLA (Multi-head Linearized Attention) forward pass
"""
bsz, q_len, _ = hidden_states.size()
# 1. Query projection and split
q = self.q_up_proj(
self.q_down_layernorm(
self.q_down_proj(hidden_states)
)
)
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(
q,
[self.qk_nope_head_dim, self.qk_rope_head_dim],
dim=-1
)
# 2. Key/Value projection and split
compressed_kv = self.kv_down_proj(hidden_states)
compressed_kv, k_pe = torch.split(
compressed_kv,
[self.kv_lora_rank, self.qk_rope_head_dim],
dim=-1
)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv = (
self.kv_up_proj(self.kv_down_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
k_nope, value_states = torch.split(
kv,
[self.qk_nope_head_dim, self.v_head_dim],
dim=-1
)
# 3. Apply RoPE to position-dependent parts
kv_seq_len = value_states.shape[-2]
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
# 最终 Q, k, V 的 Shape 都希望是 (batch_size, num_heads, seq_len, head_dim)
# 其中 q / k 的 head_dim = self.qk_nope_head_dim + self.qk_rope_head_dim
# v 的 head_dim = self.v_head_dim
# 4. Combine position-dependent and independent parts
query_states = torch.empty(
bsz, self.num_heads, q_len, self.q_head_dim,
device=k_pe.device
)
query_states[:, :, :, :self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim:] = q_pe
key_states = torch.empty(
bsz, self.num_heads, q_len, self.q_head_dim,
device=k_pe.device
)
key_states[:, :, :, :self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim:] = k_pe
# 5. Compute attention scores
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3))
attn_weights = attn_weights / math.sqrt(self.q_head_dim)
if attention_mask is not None:
attn_weights = torch.masked_fill(
attn_weights,
attention_mask == 0,
float("-inf"),
)
# 6. Softmax and dropout
attn_weights = F.softmax(
attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = F.dropout(
attn_weights, p=self.attention_dropout, training=self.training)
# 7. Compute attention output
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).reshape(bsz, q_len, -1)
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
# 写一个测试函数
def test_mla():
config = DeepseekConfig(
hidden_size=7168,
num_heads=16,
max_position_embeddings=1024,
rope_theta=128000,
attention_dropout=0.1,
q_lora_rank=1536,
qk_rope_head_dim=64,
kv_lora_rank=512,
v_head_dim=128,
qk_nope_head_dim=128,
attention_bias=False,
)
mla = MLA(config)
x = torch.randn(2, 1024, 7168)
position_ids = torch.arange(
config.max_position_embeddings,
).unsqueeze(0).expand(
x.size(0), -1
)
attn_output, attn_weights = mla(x, position_ids=position_ids)
print(attn_output.shape)
print(attn_weights.shape)
test_mla()
带有矩阵吸收的 MLA 算法
先参考这一篇知乎的解读: https://www.zhihu.com/question/655172528/answer/3492701118 ,之后我会做视频讲解
