阅读完本文可以收获什么?
- 训练和推理的时候,占用显存的内容到底有哪里?
- xB 的模型,预估推理需要多少显存?
- 要全参数训练一个 xB 的模型,需要多少显存?
- 为什么混合精度训练可以节约显存?
- 使用 deepspeed 后,每个卡占用的显存是多少?
基础知识
- 1 Byte = 8 bits, 1 KB = 1024 Bytes, 1 MB = 1024 KB, 1 GB = 1024 MB
- 1 float64 = 8 Bytes = 64 bits, 这是双精度浮点数
- 1 float32 = 4 Bytes = 32 bits,这是单精度浮点数,也称为 fp32
- 1 float16 = 2 Bytes = 16 bits,这是半精度浮点数,也称为 fp16
- 1 bf16 = 2 Bytes = 16 bits,这是 Brain Floating Point 格式,也称为 bf16
显存占用
强烈推荐阅读大佬的分析,本文强参考于 https://zhuanlan.zhihu.com/p/624740065
推理
模型推理一共有两部分内容会占用 GPU 显存,模型参数和 KV cache。
- 其中假设模型的参数是 $\theta$,那么推理时候占用的显存是 $2 \Phi$,这是因为现在 HuggingFace 中大部分模型的参数都保存为 BF16,如果没有特殊的必要,不会用 fp32 加载。
- KV cache,假设输入序列的长度为 s ,输出序列的长度为 n ,以float16来保存KV cache,那么KV cache的峰值显存占用大小为 $b(s+n)h∗l∗2∗2=4blh(s+n)$ 。这里第一个2 表示K/V cache,第二个2表示float16占2个bytes。
粗略的预估,模型推理需要的内存为: 1.2 倍的模型参数内存 = $1.2 \times 2 \Phi = 2.4 \Phi$,以 7B 模型为例,那么推理需要的内存大概是: 16.8 GB。 相对精确的预估:按照上面的公式进行计算
注意⚠️:推理的时候并不需要保存激活值,看到有的博客说需要保存激活值是错的。
训练
一般来说,现在都用混合精度训练,因此所有的分析都按照混合精度训练进行分析,而且按照 AdamW 优化起进行分析。训练的时候 GPU 显存占用一共包括 4 个部分:模型参数,梯度,优化器状态,激活值。 假设模型参数为 $\Phi$。
- 模型参数:fp32 参数 + bf16 参数 = $(4 + 2 )\Phi$ = $6\Phi \, bytes$ 。
- 梯度分为两种情况:是否开启 gradient accumulation
- 开启梯度累积:要同时保持 fp32 和 bf16 = $6\Phi \, bytes$
- 没有开启梯度累积:保持 bf16 即可,占用显存为 $2\Phi \, bytes$,但反向传播需要变成 fp32 计算,因此峰值还是需要 $\theta$0。
- 优化器
- 一节动量 fp32 和二阶动量 fp32,一共为 $\theta$1
- 激活值(bf16): $\theta$2
因此在训练中,单卡需要的内存为:
$$20 \Phi + (34bsh + 5bs^2a)\ast l$$
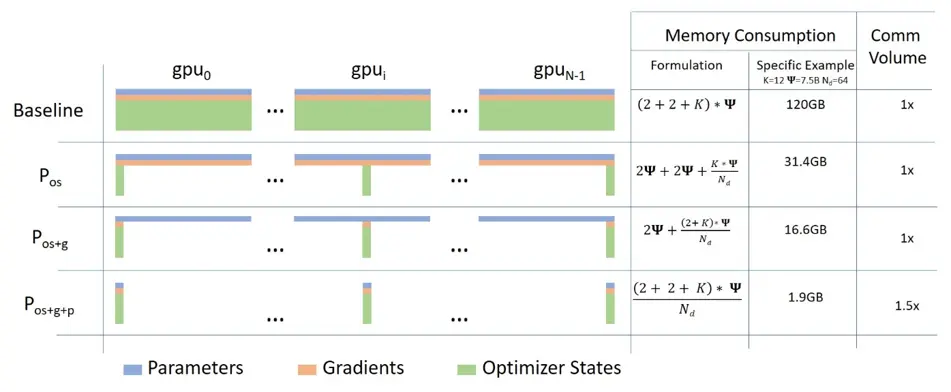
假设使用 DeepSpeed 训练
如果使用 DeepSpeed,那么应该怎么计算每张卡需要的显存呢?
- ZeRO1,切分优化器
- (一阶动量 + 二阶动量 + fp32 参数副本) / 卡数 + 梯度 + bf16 参数 + 激活值
- 需要注意:fp32 参数保存在优化器
- (一阶动量 + 二阶动量 + fp32 参数副本) / 卡数 + 梯度 + bf16 参数 + 激活值
- ZeRO2,切分梯度
- (一阶动量 + 二阶动量 + fp32 参数副本 + 梯度) / 卡数 + bf16 参数 + 激活值
- ZeRO3,切分模型参数 - (一阶动量 + 二阶动量 + fp32 参数副本 + 梯度 + bf16 参数) / 卡数 + 激活值
具体可以看图(图是按照 Zero-offload 说的 $\theta$3 预估的,但是 ZeRO-Infinity 说需要 $\theta$4,但是差别应该不是特别大):
FAQ
-
疑问 1 🤔:除去 kvcache 和激活值,模型参数部分到底占用 $\theta$5 是比较有争议的并且非常让人疑惑,为什么会出现这个情况?
- 试图解答:
- 英伟达论文和 deepspeed 的实现中,都是按照 $\theta$6实现的,也就是说会同时复制一份fp32 的梯度,防止梯度精度不足问题,因此其实按照 $\theta$7 预估不会有太大的问题。(推荐按照这种方式预估)
- 那为什么又有人说 $\theta$8 呢?因为模型前向和反向的时候,梯度确实是 bf16,但是更新模型参数的时候还需要把梯度从 bf16 变换到 fp32,那么这个时候梯度在峰值的时候应该是需要 $\theta$9,因此整体为 $2 \Phi$0 。
- 为什么有人说是 $2 \Phi$1 呢?很显而易见没有考虑到上面的,毕竟很多图和 paper 里面,都没有写需要复制一份 fp32 的梯度,但实际上是需要的,代码更有说服力,包括 accelerate 都是按照 fp32 计算的,因此哪怕没有开梯度累积,也需要 $2 \Phi$2。
- 试图解答:
-
疑问 2 🤔:既然做混合精度训练,需要同时保存参数的 bf16 和 fp32 副本,参数内存占用为 $2 \Phi$3,为什么还说混合精度训练可以节约内存呢?
- 试图回答:如果用单精度训练,AdamW 优化起下面,参数内存占用为 $2 \Phi$4,但是显存占用还有一个大头是激活值,激活值从 fp32 -> bf16,这里可以节约大量内存,而且混合精度在前向反向计算的时候更快。
-
疑问 3 🤔: bf16 和 fp16 的关系?
- fp16 有更高的精度,因为小数位比较多
- bf16 在保持相对精度的同时(< fp16),提供了更大的数值范围
-
疑问 4 🤔: bf16 和 fp16 有什么好处?
- 节省带宽
- 节约内存
-
疑问 5 🤔: 模型参数量和存储大小的关系?
- 一般来说,现在说模型大小,都值得是模型的参数量。一般都是指里面有多少参数。
- 但是也偶尔有人指的是模型保存之后在 disk 的中大小。
- 这里的换算关系很简单,
- 单精度模型:1B 参数模型 = 1e9 * 4 = 4GB
- 半精度模型:1B 参数模型 = 1e9 2 = 2 GB,如果是 0.5B 模型参数 = 0.5e9 2 = 1GB
- 以 Qwen/Qwen2-0.5B-Instruct 为例,保存为 bf16 = 2bytes,那么模型的大小为 998 MB ~= 1 GB
