0. 阅读收获 (takeaway)
读完本文,你将了解:
- KV Cache 的原理以及它为什么对 LLM 推理如此重要
- Prefill 与 Decode 两个推理阶段的区别
- Compute Bound 与 Memory Bound 背后的直觉
- 一个很好的问题:Prefill 阶段为什么需要计算所有 token 的 Q?
- Prompt Caching(前缀缓存)的工作原理
KV Cache 和 Prompt Cache 对于 Agent 设计的影响:
- Agent 系统中的 Prompt Caching 设计(上):Cache 破坏、Prompt 布局与工具管理 —— 为什么 Agent 更需要 Cache、什么会破坏 Cache、三家工具管理方案对比
- Agent 系统中的 Prompt Caching 设计(下):上下文管理与子代理架构 —— 上下文压缩、Plan 模式演进、子代理 Cache 友好设计
1. 什么是 KV Cache?
1.1 Autoregressive 生成的重复计算问题
大语言模型(LLM)的文本生成是 自回归(autoregressive) 的:每次只生成一个 token,然后把这个 token 拼到已有序列后面,再预测下一个。
用伪代码表示就是:
# 自回归生成的朴素实现
output_tokens = []
for step in range(max_new_tokens):
# 每一步都要把 整个序列 送进模型
logits = model(input_tokens + output_tokens)
next_token = sample(logits[-1]) # 只用最后一个位置的 logits
output_tokens.append(next_token)
Q: 问题出在哪?
每一步生成,模型都要对所有历史 token 重新做 Attention 计算——包括 Q、K、V 矩阵乘法。但对于已经出现过的 token,它们的 K 和 V 其实不会变(因为参数没变、token 没变),唯一在变的只有 "最新生成的那个 token" 对应的 Q、K、V。
这就引出了一个自然的优化思路:能不能把已经算过的 K 和 V 缓存起来,下次直接用?
1.2 KV Cache 的核心思想
KV Cache 的核心思想非常直接:
把每一层 Attention 中、每个已生成 token 对应的 K 向量和 V 向量缓存下来。后续生成新 token 时,只需要计算新 token 自己的 Q、K、V,然后将新的 K、V 追加到缓存中,用缓存里的完整 K、V 序列做 Attention。
这样一来,生成第 $t$ 个 token 时,Attention 的计算从 $O(t \times d)$(重算所有 token 的 K、V)降低到 $O(d)$(只算 1 个新 token 的 K、V),避免了绝大部分重复计算。
用带 KV Cache 的伪代码表示:
# 带 KV Cache 的生成
kv_cache = {} # 每一层缓存 K, V
for step in range(max_new_tokens):
if step == 0:
# 第一步:处理所有 input tokens,填充 cache
logits, kv_cache = model(input_tokens, kv_cache=None)
else:
# 后续步:只送入上一步生成的 1 个 token
logits, kv_cache = model([last_token], kv_cache=kv_cache)
next_token = sample(logits[-1])
last_token = next_token
1.3 KV Cache 显存占用
KV Cache 不是免费的——它用显存换计算。随着生成序列变长,KV Cache 占用的显存会线性增长。
具体公式(假设 float16 存储):
其中:
- $b$ = batch size
- $l$ = Transformer 层数
- $h$ = hidden size
- $s$ = 输入序列长度
- $n$ = 输出序列长度
- 4 = 2(K 和 V)× 2(float16 占 2 bytes)
这个公式的详细推导和具体数值例子,可以参考我之前的文章 LLM 大模型训练-推理显存占用分析。这里只需要记住一个直觉:序列越长,KV Cache 越大。这也是为什么后续会有 GQA(Grouped Query Attention)、DeepSeek MLA 等 KV Cache 压缩技术出现。
2. Prefill vs Decode:推理的两个阶段
理解了 KV Cache 之后,我们可以把 LLM 推理过程清晰地分成两个阶段:Prefill 和 Decode。这两个阶段的计算特性截然不同,理解它们的区别对后面理解 Prompt Cache 非常关键。
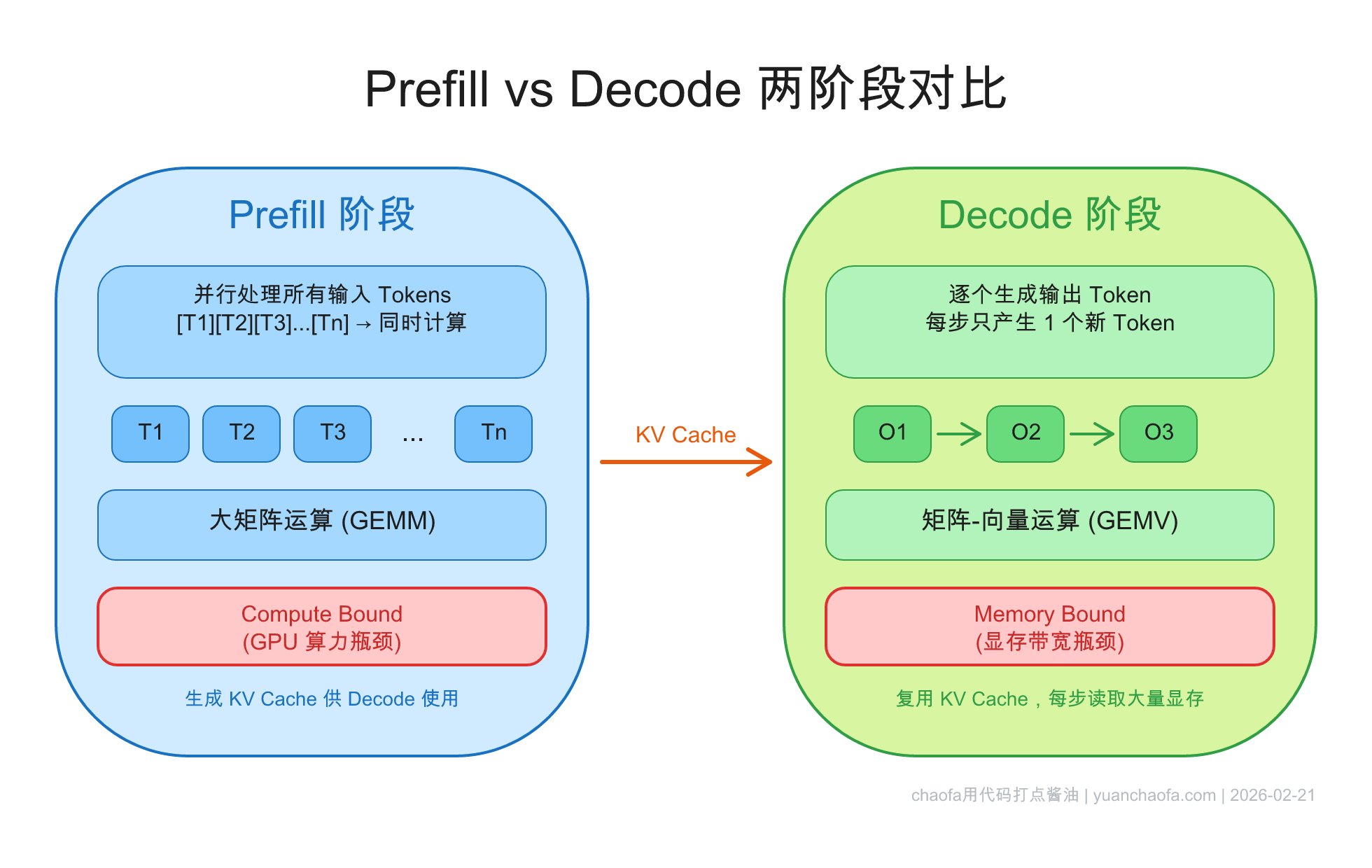
2.1 Prefill 阶段(并行处理 input tokens → Compute Bound)
Prefill 阶段就是上面伪代码中 step == 0 的那一步:模型一次性处理所有输入 token(system prompt + user message),为每一层、每个 token 计算出 K 和 V 并存入 cache。
关键特点:
- 所有输入 token 可以并行处理(它们之间的 Attention mask 是 causal 的,但计算可以用矩阵乘法一次完成)
- 计算量大:$n$ 个 token × 所有层 × Q/K/V 矩阵运算
- Compute Bound:GPU 的算力是瓶颈
2.2 Decode 阶段(逐 token 生成 → Memory Bound)
Decode 阶段就是后续的 step > 0:每一步只输入 1 个 token,利用 KV Cache 做 Attention,生成下一个 token。
关键特点:
- 每步只处理 1 个 token(无法并行,因为下一个 token 依赖上一个的输出)
- 每步的计算量其实不大——1 个 token 的 Q 乘以 cache 中所有 K/V
- 但每步都要从显存读取整个 KV Cache
- Memory Bound:GPU 的显存带宽是瓶颈
2.3 Compute Bound vs Memory Bound
这里解释一下 Compute Bound 和 Memory Bound 的含义,核心概念是 Arithmetic Intensity(算术强度):
- Compute Bound:算术强度高,GPU 的计算单元忙不过来,数据搬运不是瓶颈。Prefill 就是这种情况——大矩阵乘法,计算密集。
- Memory Bound:算术强度低,GPU 的计算单元在等数据从显存搬过来。Decode 就是这种情况——每步只有 1 个 token 的小矩阵运算,但要读取整个 KV Cache。
用一个直觉来理解:
- Prefill 像是"一次批量处理 1000 个快递"——流水线拉满,打包效率高
- Decode 像是"每次只来 1 个快递"——打包机器空闲大半时间,瓶颈在于快递从仓库取出来的速度
2.4 一个很好的问题:Prefill 为什么要计算所有 token 的 Q?
这个问题来自一位读者在 GitHub Discussion 的提问,我觉得是一个非常好的问题:
既然我们只需要预测 next token,Prefill 阶段不是只需要最后一个 token 的 Q 吗?为什么要计算所有 token 的 Q?
乍一看很有道理——Attention 的输出 $\text{softmax}(QK^T / \sqrt{d})V$ 中,我们只需要最后一个位置的结果来预测 next token。那 K、V 确实需要全算(因为最后一个 Q 要和所有 K 做 attention),但 Q 为什么不能只算最后一个?
答案的核心是:Decoder 有很多层。
如果 Transformer 只有一层,那确实,我们只需要最后一个 token 的 Q。但实际的 Decoder 有几十层,上一层所有位置的输出是下一层所有位置的输入:
- 第 1 层:为了得到所有位置的 K、V(这些 K、V 要存入 cache),需要知道所有位置的输入。而第 1 层的输入就是 token embedding,所以 Q、K、V 都要算全部位置。
- 第 2 层:第 2 层的输入是第 1 层的输出。第 1 层的输出取决于 Attention 的完整计算——包括所有位置的 Q。因此第 2 层的 K、V 计算依赖于第 1 层所有位置的 Q 计算结果。
- 第 N 层:同理,依赖前面所有层的完整输出。
看图:
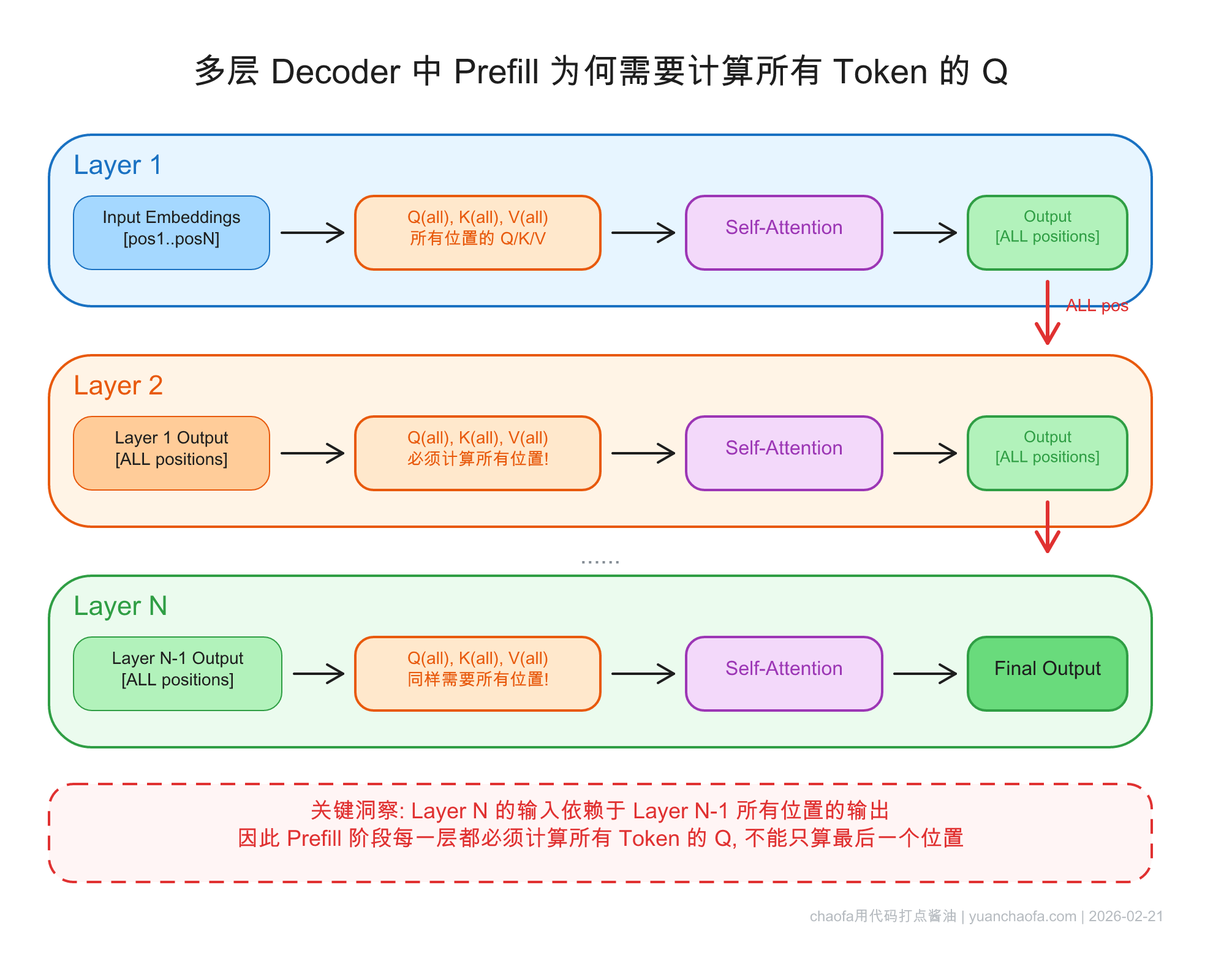
所以结论是:
Prefill 必须计算所有 token 的 Q,不是因为最终预测需要,而是因为每一层的 K、V 缓存依赖于上一层所有位置的完整输出,而上一层的完整输出需要所有位置的 Q 参与计算。
这也解释了为什么 Prefill 阶段是 Compute Bound——它确实需要做大量计算,不是在浪费。
2.5 TTFT vs TPOT
从用户体验的角度,两个阶段对应两个不同的延迟指标:
- TTFT(Time To First Token):用户发送请求到看到第一个输出 token 的时间。主要由 Prefill 阶段决定。
- TPOT(Time Per Output Token):生成每个后续 token 的平均时间。主要由 Decode 阶段决定。
对于输入很长的场景(比如长文档问答、Agent 的多轮对话),Prefill 阶段的耗时会显著增加 TTFT。
这就引出了一个关键问题:如果我们能跳过 Prefill 中那些"之前已经算过"的部分,是不是就能大幅降低 TTFT?这就是 Prompt Cache 要解决的问题。
3. Prompt Cache(前缀缓存)
3.1 从 KV Cache 到 Prompt Cache
前面说的 KV Cache 是单次请求内部的优化——生成过程中缓存已算过的 K、V,避免重复计算。
Prompt Caching(前缀缓存) 则是跨请求的优化:
如果两次 API 调用的 prompt 有相同的前缀,那么第二次调用可以直接复用第一次 Prefill 阶段算出来的 KV Cache,跳过前缀部分的 Prefill 计算。
这对于以下场景特别有价值:
- 多轮对话:每轮对话的 prompt 都以之前的对话历史作为前缀
- 相同 system prompt:同一个应用的所有请求共享相同的 system prompt 前缀
- Agent 系统:Agent 每一步的 prompt 都是上一步的 prompt 加上新的 action/observation
3.2 前缀匹配机制
Prompt Cache 的匹配规则非常严格:
必须从第一个 token 开始完全一致,一个 token 的差异就会导致该位置之后的 cache 全部失效。
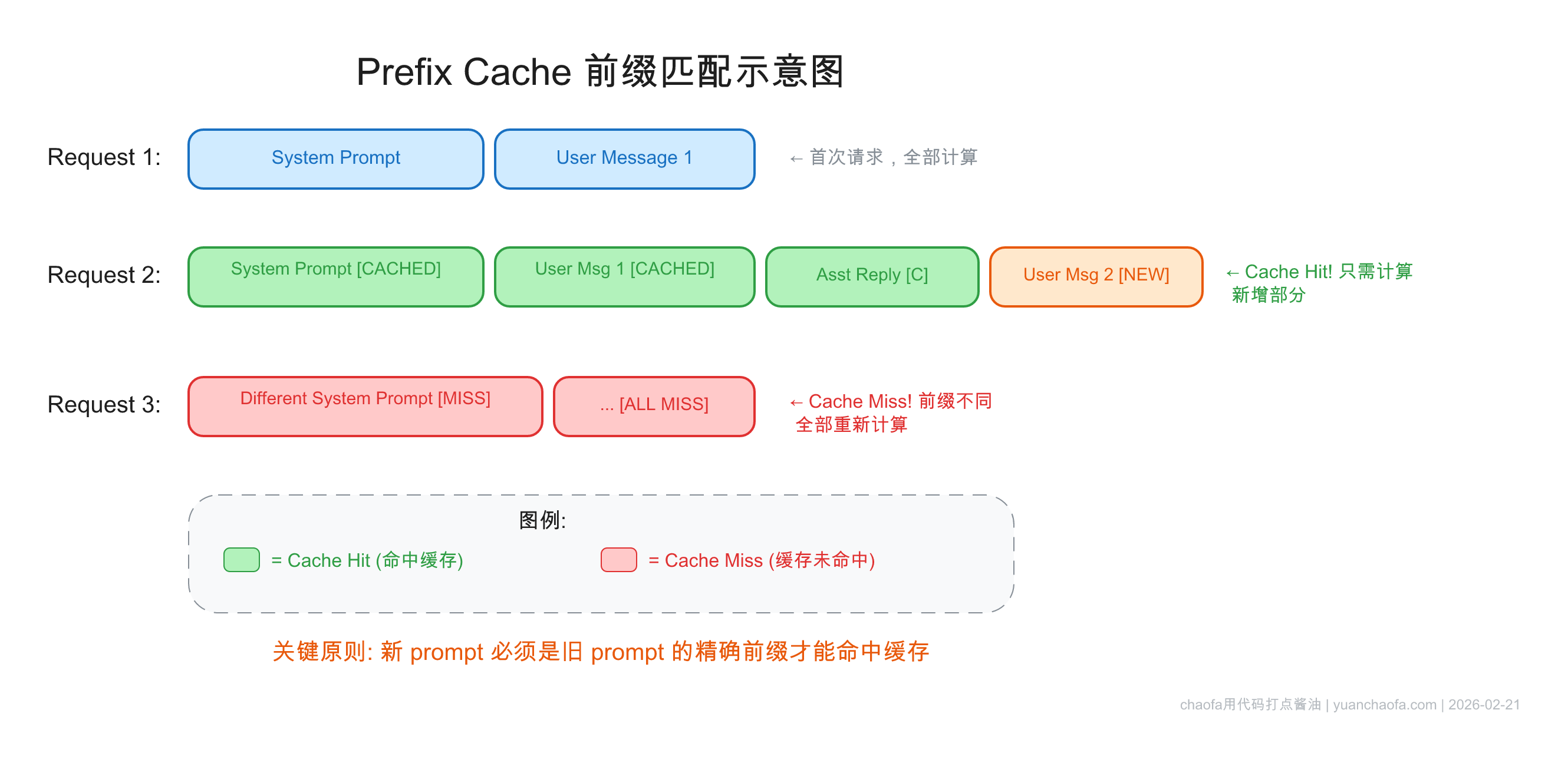
举个例子:
| 请求 | 内容 | Cache 命中情况 |
|---|---|---|
| 请求 1 | [System Prompt][User: Hello] |
无 cache,全部计算 |
| 请求 2 | [System Prompt][User: Hello][Assistant: Hi][User: 你好] |
[System Prompt][User: Hello] 部分 cache hit |
| 请求 3 | [Modified System Prompt][User: Hello] |
完全 miss,因为第一个 token 就不一样了 |
这个"前缀精确匹配"的约束,是后面 Agent 系统设计的核心基础。在下一篇文章中,我们会详细讨论 Claude Code、Manus、OpenAI Codex 如何围绕这个约束设计整个系统架构。
3.3 开源推理引擎的实现
在开源推理引擎中,Prompt Cache(通常叫 Prefix Caching 或 Automatic Prefix Caching)已经是标配功能:
- vLLM:通过
--enable-prefix-caching开启,使用 hash-based 的 block 管理机制。将 KV Cache 按固定大小的 block 存储,相同前缀的 block 可以在不同请求间共享。 - SGLang:默认开启 RadixAttention,用 Radix Tree(基数树)管理 KV Cache 前缀。相比 vLLM 的 hash 方案,Radix Tree 在前缀共享上有天然优势——可以高效处理多层级的前缀共享。
这些引擎的实现细节不是本文重点,关键是理解:Prompt Cache 在推理引擎层面已经是成熟技术,无论你用开源引擎自部署还是调用商业 API,都可以获得这个优化。
4. 总结与预告
让我们回顾一下本文的核心脉络:
- KV Cache 解决了自回归生成中的重复计算问题,是 LLM 推理的基础优化
- Prefill 阶段并行处理所有输入 token(Compute Bound),Decode 阶段逐个生成 token(Memory Bound)
- Prefill 必须计算所有 token 的 Q,因为多层 Decoder 的层间依赖
- Prompt Cache 把 KV Cache 的优化从"单次请求内"扩展到"跨请求",通过前缀匹配复用已计算的 KV Cache
- 前缀精确匹配的约束,决定了 Prompt Cache 的使用方式——任何位置的改动都会破坏该位置之后的 cache
这个"前缀精确匹配"的约束,在 AI Agent 系统中变得尤为关键。Agent 每一步都要发送越来越长的 context(历史对话 + 工具调用结果),如果不精心设计 prompt 结构,cache 命中率会很低,成本和延迟都会飙升。
在接下来的两篇文章中,我会详细分析 Claude Code、Manus、OpenAI Codex 等 AI Agent 如何围绕 Prompt Cache 设计整个系统架构:
- Agent 系统中的 Prompt Cache 设计(上):Cache 破坏、Prompt 布局与工具管理 —— 为什么 Agent 更需要 Cache、什么会破坏 Cache、三家工具管理方案对比
- Agent 系统中的 Prompt Cache 设计(下):上下文管理与子代理架构 —— 上下文压缩、Plan 模式演进、子代理 Cache 友好设计
