1. TL;DR
Kimi K2.5 有几个我觉得很值得关注的点:
- 固定视觉 token 总预算下,Early Fusion + 低视觉比例(10%)全面优于 Late Fusion + 高视觉比例(50%)——这与业界常见的先训练文本模型,然后"后期大量注入视觉数据"的做法相反
- Zero-Vision SFT:纯文本 SFT 即可激活视觉推理能力,人工标注的视觉轨迹数据反而损害泛化
- 跨模态双向增强:Outcome-Base 视觉 RL 不仅不损害文本能力,反而提升了 MMLU-Pro(+1.7)、GPQA-Diamond(+2.1)等文本 benchmark
- Agent Swarm(PARL):冻结 sub-agent、只训 orchestrator,通过 RL 学习动态任务分解与并行调度,延迟降低 3-4.5x
- Toggle:交替 budget-limited 和 standard scaling 阶段,解决 length overfitting,减少 25-30% output token 同时性能几乎无损
历史上比较相关的文章,建议对照阅读:
- Kimi K1.5: 深度解读 Kimi-K1.5,真正了解 RL 数据是怎么筛选的
- Kimi K2 (Thinking): Kimi K2 和 K2 Thinking 深度解读:从预训练优化到 Agentic 能力训练的完整流程
- DeepSeek R1: 自顶向下方式深度解读 DeepSeek-R1
本文虽然迟到,但是这篇 paper 真的很值得阅读,感谢老板 push 我做这个分享 🤣
2. 多模态联合训练:反共识的发现(重点 1)
这是本文我认为最值得关注的部分之一。
在 K2.5 之前,业界做多模态训练的普遍做法是:先训练一个强大的纯文本模型,然后在训练后期以高比例(50%+)集中注入大量视觉数据。Kimi K2.5 的消融实验挑战了这一范式。
2.1 消融实验:Early Fusion + 低比例的优势
Table 1 的核心对比如下(固定总视觉 token 预算):
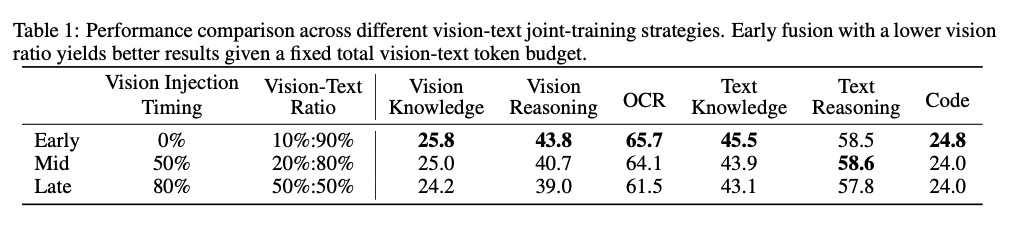
关键结论:Early Fusion + 10% 视觉比例在几乎所有指标上全面优于 Late Fusion + 50% 视觉比例(仅 Text Reasoning 58.5 vs 58.6 略低于 Mid)。
这里需要理解实验设计的约束:三种策略消耗的视觉 token 总量是相同的。Late Fusion 在训练后 80% 才注入视觉数据,为了消化相同总量的视觉 token,它需要把视觉比例提到 50%;而 Early Fusion 从头就混入视觉数据,10% 的比例就能覆盖相同的总量。

Appendix B.1 还展示了一个有趣的 dip-and-recover 现象:Late Fusion 在注入视觉数据时,文本能力会先显著下降再逐渐恢复(modality domain shift),后期强行注入大量视觉数据会对已经稳定的文本表征造成冲击。而 Early Fusion 的训练曲线保持平稳,没有这种 domain shift shock——因为两种模态从一开始就在共同演化。
不过我个人觉得这个现象好像不是很明显的样子,没有我画的图这么明显,还是我不会读图?
2.2 Zero-Vision SFT:纯文本 SFT 激活视觉能力
预训练之后的模型虽然已经能"看懂"图像,但还不能做复杂的视觉操作(裁剪、测量、计数等)。传统做法是人工标注视觉轨迹数据来教模型。
Kimi K2.5 提出了一个反直觉的方案——Zero-Vision SFT:SFT 阶段只用纯文本数据,所有图像操作都通过 IPython 代码来代理。模型学会用代码描述视觉操作(binarize、crop 等),而不是直接学习像素级的操作轨迹:
# 问题:计算图中绿色区域占比
# 回复
<thought> 需要用 binarization 分离绿色区域 </thought>
import cv2
img = load_image("input.png")
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, lower_green, upper_green)
ratio = np.sum(mask > 0) / mask.size
答案:绿色区域占比 32.5%
论文做了对比实验:text-vision SFT(加入了人工标注的视觉轨迹数据)效果反而更差。这是因为缺乏足够高质量的视觉数据,加上模型会过拟合于特定标注风格。
个人理解:代码作为桥梁提供了精确的操作语义——cv2.inRange 就是精确的颜色过滤,不存在歧义。同时,前期联合预训练已经建立了视觉-文本的对齐,使得这种泛化成为可能。模型学会的是"用程序化方式处理视觉信息"的抽象能力,而不是记忆特定的视觉操作模式。这也呼应了后面预训练数据中 image-code paired data(HTML/React/SVG 代码 + 对应渲染截图)的设计——代码是一种既能被精确验证、又能描述视觉操作的通用语言。
2.3 跨模态双向迁移
这是另一个反直觉的发现。视觉 RL 训练之后,不仅视觉能力提升了,文本 benchmark 也提升了:
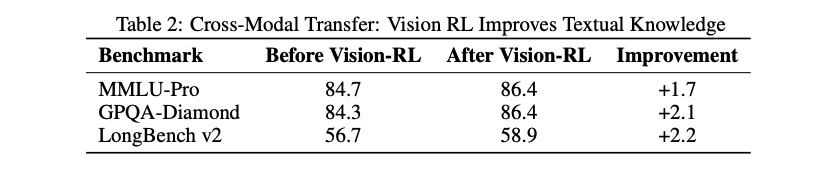
这是因为:视觉 RL 增强了模型对结构化信息提取的校准能力(calibration),这种能力迁移到了类似需要结构化信息提取的文本任务中。
值得注意的是 K2.5 联合多模态 RL 的设计选择:RL 训练是按能力维度(knowledge / reasoning / coding / agentic)来组织 domain 的,而不是按模态(text / vision)分开训练。这和 DeepSeek-GRM 跨模态优化的思路一致——按能力组织确保了同一能力维度下的文本和视觉任务共享 reward 信号,最大化了跨模态迁移。
3. Agent Swarm:RL 训练出来的并行 Agent 编排(重点 2)
3.1 顺序执行的瓶颈
现有的 Agent 系统(包括 Kimi K2 Thinking)大多是单 agent 顺序执行:每一步推理都依赖上一步的结果。这意味着任务复杂度增加时,执行时间线性增长,上下文窗口也很快被占满。对于需要大规模信息检索和多源交叉验证的复杂任务,这种线性增长是不可接受的。
3.2 PARL 架构设计
K2.5 提出了 Agent Swarm,核心是 PARL(Parallel-Agent Reinforcement Learning)框架。
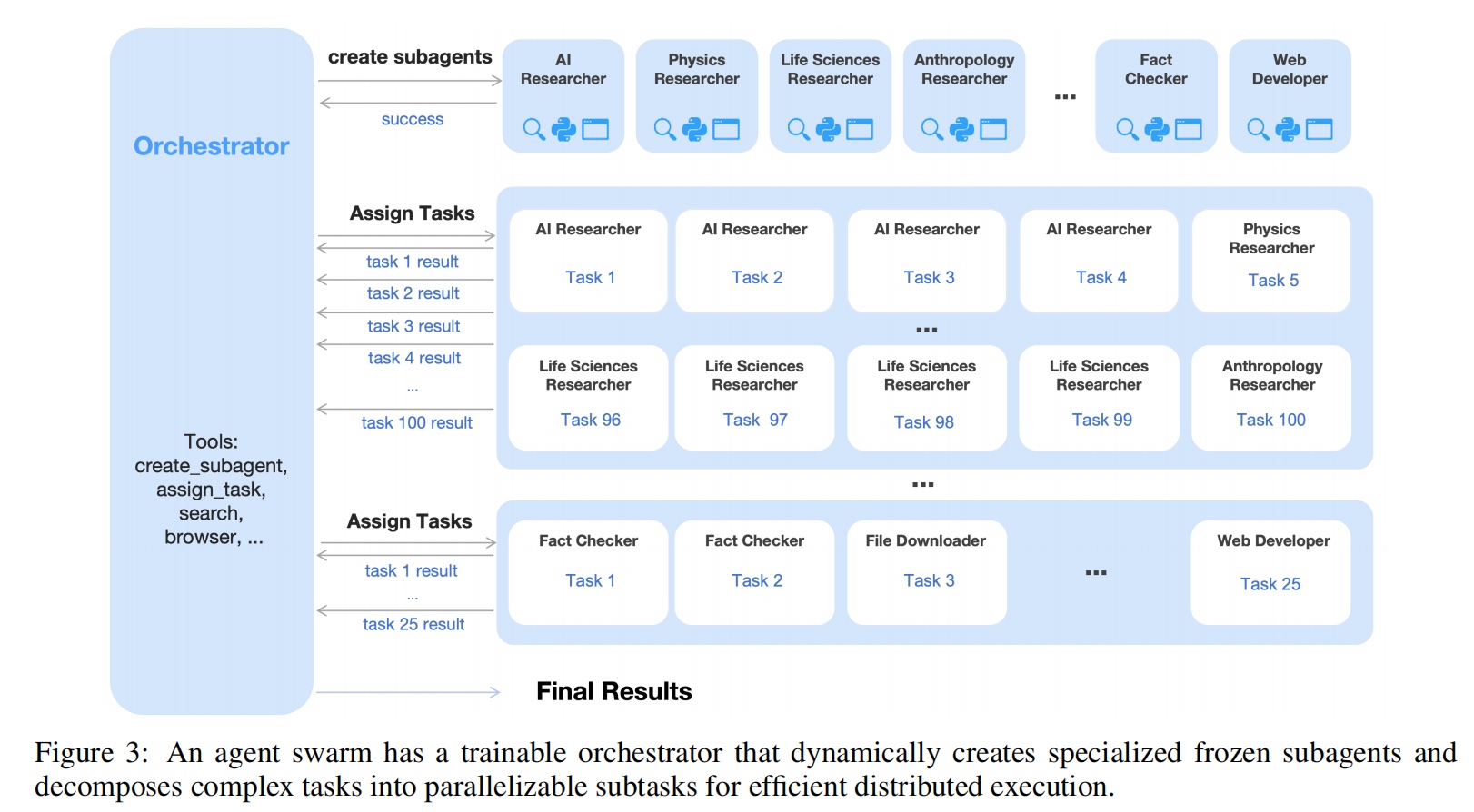
核心设计是 可训练 Orchestrator + 冻结 Sub-agents。Sub-agents 从训练过程中间 checkpoint 提取,参数冻结不参与 RL 优化。
为什么不做端到端的 co-optimization? 有两个原因:
- Credit assignment ambiguity:最终结果正确不代表所有 sub-agent 都执行正确,端到端训练无法准确地把 reward 分配给各个 sub-agent
- Training instability:多 agent 联合优化的梯度问题,尤其是 sub-agent 的输出经过外部工具调用后梯度不可传播
因此 sub-agent 的输出被视为"环境观测"(environment observation),orchestrator 只观测 sub-agent 的输入→输出映射,学习的是何时创建、如何分配、何时聚合。
个人理解:这让人想到多 Agent 群体通信和协同进化的思路。K2.5 的 Agent Swarm 是一个初步探索——orchestrator 通过 RL 学会了动态创建异构 sub-agent 并调度。注意这里的 sub-agent 不是预设的固定角色(如 Coder/Researcher/Writer),而是根据任务动态创建的(如"Quantum-Researcher"、"Pharma-Analyst"),这种专门化是涌现的,不是预设的。
3.3 PARL Reward 设计
训练并行编排器需要解决两个典型的失败模式。PARL 设计了三项 reward:
| 组件 | 功能 | 解决的失败模式 |
|---|---|---|
| $r_{parallel}$ | 奖励创建 sub-agent 的行为 | Serial Collapse(串行坍缩):orchestrator 退化为单 agent 顺序执行,完全不用并行 |
| $r_{finish}$ | 奖励 sub-agent 的完成率 | Spurious Parallelism(虚假并行):创建一堆 sub-agent 但不完成任务,只是刷 $r_{parallel}$ |
| $r_{perf}$ | 任务级最终性能 | 真正的优化目标 |
训练过程中 $\lambda_1, \lambda_2$ 逐渐退火到 0,确保最终只优化 $r_{perf}$。这是一种常见的 RL 训练技巧:先用辅助 reward 做 shaping 帮 agent 跳出局部最优,再让辅助 reward 消失回归真实目标。
举个具体例子:假设任务是"调研量子计算在药物发现中的最新进展并撰写综述":
- 如果 orchestrator 自己一步步搜索、阅读、总结,不创建任何 sub-agent(Serial Collapse),$r_{parallel} = 0$,总 reward 较低
- 如果 orchestrator 创建了 5 个 sub-agent 但只有 1 个完成了子任务(Spurious Parallelism),$r_{finish}$ 因为低完成率而很低
- 理想情况:orchestrator 创建 3 个 sub-agent(量子计算综述 / 药物研发进展 / 交叉应用案例),都成功完成并返回结果,orchestrator 综合出高质量报告——三项 reward 都高
3.4 Critical Steps:并行效率的正确度量
如何度量并行执行的实际时间成本?论文定义了 Critical Steps(关键步数):
其中 $S_{main}^{[t]}$ 是第 $t$ 阶段主 agent 的步数,$S_{sub, i}^{[t]}$ 是第 $t$ 阶段第 $i$ 个 sub-agent 的步数。
这个定义等价于计算图的关键路径长度:每个阶段的耗时取决于最慢的那个 sub-agent。通过约束 Critical Steps 而非 Total Steps,模型被激励去做真正减少 wall-clock 时间的有效并行,而不是创建大量但低效的并发。
实验结果方面,Agent Swarm 在搜索类 benchmark 上带来了 3x-4.5x 的延迟降低,同时准确率也有提升(比如 BrowseComp 从 60.6% 提升到 78.4%)。
3.5 Agent Swarm 作为主动 Context Management
Agent Swarm 还有一个值得关注的副产品:主动的上下文管理。
传统的 context management 都是被动策略——上下文快满了就丢弃旧内容(Discard-all)、隐藏工具输出(Hide-Tool-Result)或做摘要(Summary)。这些都是信息已经膨胀之后的补救。
Agent Swarm 提供了一种主动的 context sharding 策略:每个 sub-agent 维护独立的局部 context,只有任务相关的输出返回给 orchestrator。orchestrator 不需要看到每个 sub-agent 搜索了什么网页、执行了什么中间代码,只需要看到最终结论。这实现了信息的局部性和模块化。
4. RL 训练算法创新(选读)
4.1 Token-level Clipping 机制
K2.5 的 RL 优化目标:
其中 $\log\text{ratio} = \log \pi_\theta(a_t|s_t) - \log \pi_{old}(a_t|s_t)$。注意 Clip 作用于概率比值(ratio)而非 log-ratio,最后的 $(\log\text{ratio})^2$ 项是 KL 正则化项,用于进一步约束策略偏移。
与标准 PPO clipping 的关键区别:K2.5 严格基于 log-ratio 的区间 $[\alpha, \beta]$ 做 gradient masking,不依赖 advantage 的符号来决定 clipping 方向。直觉上,PPO 的 clipping 是"根据 advantage 好坏来决定是否限制更新幅度",而 K2.5 是"不管 advantage 好坏,只要策略偏移超过阈值就截断梯度"。
这对 K2.5 的场景很重要:在长程多步工具使用任务中(如 Agent Swarm 的上百步工具调用),trajectory 非常长,off-policy divergence 在长 trajectory 中会被逐步放大。更严格的 token-level 约束能更好地控制策略偏移。这也是从 Kimi K1.5 延续过来的设计思路。
4.2 Toggle:Token 效率优化
问题定义:RL 训练中有一个矛盾——如果用 budget 约束(限制输出长度)来提升 token 效率,模型会学到"短答案捷径"(length overfitting),导致在测试时无法利用更多的 compute 进行深度推理。
回顾一下进化路线:K1.5 的做法是在 reward 中直接加长度惩罚,公式很简单——越长奖励越小。这种方式比较粗暴,容易导致模型在需要深度推理时也输出过短的回答。
K2.5 的 Toggle 通过交替训练更优雅地解决了这个矛盾:每 m 个 iteration 切换一次 phase——
- Phase 0(Budget-Limited):约束输出长度,但有一个关键条件——只在模型平均准确率超过阈值 $\lambda$ 时才施加长度限制。Budget 用正确回答的 $\rho$ 分位数长度来估计。这确保了"先学对,再学短"。具体地,Phase 0 的条件 reward 公式为:
其中 $\text{budget}(x) = Q_\rho(\{\text{len}(y_i) \mid y_i \text{ is correct}\})$ 是正确回答长度的 $\rho$ 分位数,$\bar{r}_{perf}$ 是当前 batch 的平均准确率,$\lambda$ 是准确率阈值。只有当模型整体准确率已经够高($\bar{r}_{perf} > \lambda$)时,才对超过 budget 的回答施加惩罚。
- Phase 1(Standard Scaling):允许最大 token 输出,鼓励充分推理,保持 test-time scaling 能力
两个 phase 交替训练,让模型同时学会"简洁推理"和"深度推理",而不是在同一个 reward 中权衡两者。这和 AdaCoT/AdaThinking 中自适应快慢思考的思路有相通之处,但 Toggle 是在训练阶段解决问题,而 AdaCoT 是在推理阶段。
实验结果:Toggle 实现 25-30% 的 token 减少,同时性能几乎无损甚至略有提升。
4.3 Reward 体系
K2.5 的 reward 设计覆盖面非常广,这里挑几个值得关注的。
GRM(Generative Reward Models)
K2.5 使用了生成式奖励模型,和 DeepSeek-GRM 的思路一致:
- 不是二元对错判断,而是细粒度多维评估(helpfulness、contextual relevance、aesthetic quality 等)
- 覆盖多种 agent 环境:chat agents、coding agents、search agents、artifact-generating agents
- 使用多套 rubric 防止 reward hacking——如果只用一套评估标准,模型很容易找到特定的 exploit
视觉任务专用 Reward
有一些不太常见的视觉 reward 设计值得关注:
- Visual puzzle reward:合成复杂的视觉谜题(找规律、空间推理等),用 LLM verifier(K2)提供反馈。这类任务很难设计 rule-based reward,所以用强模型做 judge
- 其他还包括:IoU soft matching(定位)、Gaussian-weighted distance(关键点检测)、normalized edit distance(OCR)、absolute difference(计数)
Budget-control reward
对于有明确答案的任务(数学、代码),使用 rule-based 的 outcome reward。在 Toggle 的 Phase 0 中,额外叠加 budget-control reward 来约束输出长度——当输出超过 budget 时惩罚,在 budget 内则不影响。
5. 模型架构与训练 pipeline(选读)
5.0 Foundation:从 K2 到 K2.5
K2.5 和 Kimi K2 共享同一套 MoE 架构——1T 总参数、32B 激活参数(~3.1% 激活)、384 个 Expert(每 token 激活 8 个,稀疏比 48x)。K2 的 MuonClip 优化器(Muon + QK-Clip,实现 15.5T token 零 loss spike 训练)也被原封不动地继承。需要注意的是,K2 是纯文本模型(原文:"pre-trained on 15 trillion high-quality text tokens"),K2.5 的核心工作就是增加原生多模态和 Agent 并行能力。
K2.5 在 K2 基础上的核心增量是:
| 维度 | K2 | K2.5 新增 |
|---|---|---|
| 模态 | 纯文本 | 原生多模态(文本 + 图像 + 视频) |
| 视觉编码器 | - | MoonViT-3D(基于 SigLIP-SO-400M) |
| 预训练 | 15.5T 文本预训练 | 在 K2 结构基础上三阶段:ViT → Joint → Long-context |
| 上下文长度 | 128/256k | 扩展到 262K(看表格) |
| SFT | 文本 + Agentic 数据 | 新增 Zero-Vision SFT(纯文本激活视觉) |
| Agent | 单 agent 顺序执行 | Agent Swarm(PARL 并行编排) |
| Token 效率 | — | Toggle 交替训练(-25~30% tokens) |
5.1 ViT 基础 + MoonViT-3D
先简要介绍一下 ViT(Vision Transformer)的基本原理,帮助不熟悉的读者理解后续内容。
ViT 的核心思想就是把图像当成 token 序列来处理:把图像切成若干个 patch(通常是 16x16 像素),每个 patch 就相当于 NLP 中的一个 token。然后加上位置编码(让模型知道每个 patch 在图像中的空间位置),送入标准的 Transformer Encoder 处理,最后输出视觉特征。

K2.5 使用的 MoonViT-3D 在标准 ViT 基础上做了三个关键改进:
- NaViT Packing:支持原生分辨率输入,不需要把图像 resize 到固定尺寸(传统 ViT 需要 resize 到 224x224,会损失信息)。不同分辨率的图像可以 pack 到同一个 batch
- 3D 时序压缩:处理视频时,每 4 帧为一组做 temporal pooling,实现 4x token 压缩。这让模型在相同上下文窗口内能处理 4 倍更长的视频
- 图像视频完全共享权重:图像可以看作单帧视频,图像预训练的知识可以零迁移到视频理解
MoonViT-3D 继承自 SigLIP-SO-400M,整体架构是 MoonViT-3D + MLP Projector + Kimi K2 MoE(1T 总参数,32B 激活参数,384 个 Expert,每 token 激活 8 个)。
5.2 预训练三阶段
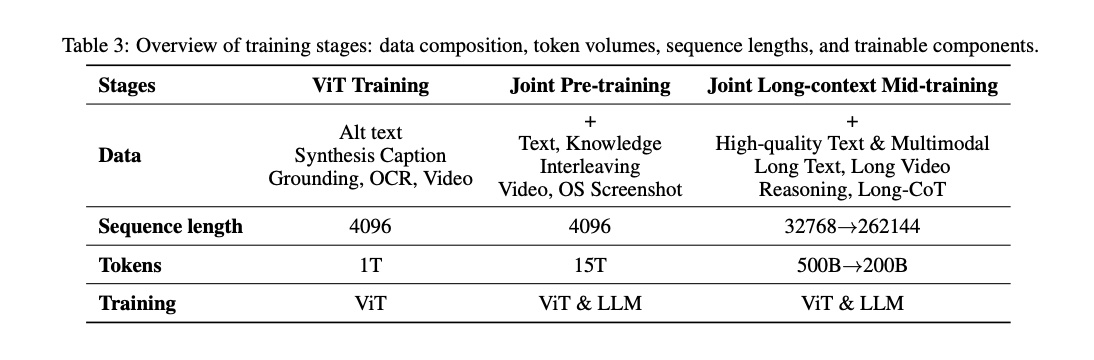
第一阶段只训练 ViT,让视觉编码器先具备基本的视觉理解能力。第二阶段开始联合训练 ViT 和 LLM——这正是前面消融实验中 Early Fusion 策略的实现,从 15T token 的联合预训练一开始就以 ~10% 的比例混入视觉数据。第三阶段逐步扩展到长上下文(32K → 262K)。
5.3 预训练数据亮点
附录 B 披露了一些有意思的数据构建细节:
代码数据增强:除了常规的代码数据,K2.5 还加入了 repo-level 的代码(完整仓库结构)、GitHub Issues / Code Reviews / Commit History。这类数据帮助模型理解代码的演进过程和协作模式,对 agentic coding 任务(如 SWE-Bench)很有帮助。
视觉数据 7 类:caption、interleaving、OCR、knowledge、video、agent、grounding。其中特别值得注意的是 image-code paired data——HTML/React/SVG 代码与其对应的渲染截图配对。这种数据直接建立了从视觉布局到代码实现的映射,对 web 相关的 agent 任务(如 OSWorld、Computer Use)至关重要。
5.4 DEP(Decoupled Encoder Process)
简要提一下 infra 层面的创新。多模态训练的一个难点是视觉编码器通常只在 Pipeline Parallelism 的第一个 stage 运行,导致负载不均。DEP 将视觉编码器解耦为独立进程,让所有 GPU 并行处理视觉数据,消除了这个瓶颈。效果是多模态训练效率达到纯文本训练的 90%。
6. 总结与思考
读完 K2.5 的论文,几个核心启发:
-
联合训练 > 分阶段训练,而且比例不是越多越好。在固定视觉 token 总预算的约束下,10% 的视觉数据比 50% 效果更好,关键在于注入时机(从头注入)而非数量。这对多模态模型的训练策略有直接的指导意义:与其在后期堆视觉数据量,不如在早期就建立跨模态的联合表示。
-
代码是跨模态的通用桥梁。Zero-Vision SFT 的成功说明代码提供了一种精确的操作语义,可以作为文本和视觉之间的桥梁。
-
Agent 并行化可以通过 RL 训练出来,而不需要预设规则。Orchestrator 通过 PARL 自然学会了何时并行、如何分配、何时聚合,这种能力具有泛化性。而且 PARL 的 reward 设计(auxiliary reward shaping + annealing)可以推广到其他需要"引导探索"的 RL 场景。
-
Token 效率优化的技术在不断演进:K1.5 的长度惩罚 reward → K2.5 的 Toggle 交替训练 → 配合 Token-level Clipping 控制策略偏移。这条技术路线越来越精细,越来越接近"让模型自主决定何时简洁、何时深入"。
从 K1.5 到 K2 到 K2.5,每一代都在前一代的基础上解决了新的核心问题,而且技术方案的设计越来越优雅。
